2023. 3. 14. 15:38ㆍ카테고리 없음
이번 포스팅에선 Selenium 라이브러리를 이용해서 웹 크롤러를 제작한 과정을 공유해보려고 한다.

Selenium이란?
서버에서 브라우저의 환경을 구현할 수 있는 오픈소스 라이브러리이다.
주로 브라우저 기반 End Test에 사용되지만 크롤링 같은 다양한 목적을 위해 사용할 수 있다.
Selenium을 사용한 이유?
크롤러를 개발할 때 처음에는 jsoup 라이브러리를 사용했다.
하지만 jsoup는 치명적인 단점이 있다.
jsoup 라이브러리는 uri 접속시 최초 로딩되는 페이지만 읽어 들일 수 있다.
요즘의 웹 페이지는 SPA 방식으로 최초에 index 페이지를 로딩하고나서 유저의 동적인 action에 의해 동적으로 페이지를 랜더링하는 방식을 사용한다.
HTML, CSS, JavaScript를 사용하는 기본적인 PWA 페이지도 최초 웹 페이지 로딩 시간을 줄이기 위해 root 페이지를 경량화하고 유저의 action에 의해 추가적으로 페이지를 동적으로 로딩하는 방식을 채택하고 있다.
따라서 jsoup는 적합하지 않고 서버에서 브라우저 환경을 똑같이 구현할 수 있는 Selenium 라이브러리를 사용했다.
WebDriver
Selenium의 핵심 코어가되는 인터페이스이다.
Chrome/Chromium, Firefox, Internet Explorer, Edge, Safari 같은 다양한 공급사의 브라우저를 사용할 수 있다.
WebDriver를 통해 실제 사용자가 브라우저를 조작하는 것처럼 브라우저를 제어할 수 있다.
텍스트를 입력하거나, 링크를 클릭하고, 마우스를 이동하는 등의 action을 제공한다.
Wait
대부분의 웹 페이지는 동적으로 생성되기 때문에 완전히 로드되기까지 일정 시간이 필요하다.
Selenium은 대기 기능을 지원하고 일정 대기 시간동안 element를 찾지 못하면 WebDriverException을 발생시킨다.
다음의 세 가지 wait를 지원한다.
- implicit wait
- explicit wait
- fluent wait
1. Implicit Wait(비추천)
암시적 대기는 모든 findElement() 함수에 대해서 최대 대기 시간을 지정하는 방법이다.
코드의 중복을 줄일 수 있다는 장점이 있지만 개인적으로 추천하지 않는다.
예시)
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));📌 Implicit Wait을 추천하지 않는 이유
Implicit Wait은 브라우저의 페이지를 자주 변경해야할 때 findElement()가 동작하기 전에 페이지가 변경되어버리는 경우가 생기기 때문에 StaleElementReferenceException 가 자주 발생하게 된다.
따라서 필자의 경우 Explicit Wait을 사용하여 element가 완전히 로드될 때까지 기다리고 element를 읽은 뒤에 페이지가 정상적으로 이동되도록 구현했다.
2. Explicit Wait(추천)
명시적 대기는 특정 element에 대해서만 최대 대기 시간을 지정하는 방법이다. Selenium에서 지원하는 조건들은 아래의 공식 문서에서 찾을 수 있다.
ExpectedConditions
An expectation for checking whether the given frame is available to switch to. If the frame is available it switches the given driver to the specified web element.
www.selenium.dev
예시)
new WebDriverWait(driver, Duration.ofSeconds(3)).until(ExpectedConditions.elementToBeClickable(By.xpath("//a/h3")));
📌 Explicit wait 와 Implicit wait 를 혼용해서 사용하면 안되는 이유
두가지 유형을 동시에 사용하면 충돌이 발생할 수 있다.
예를 들어 요소를 클릭할 수 있을 때까지 기다리는 명시적 대기와 암시적 대기가 동시에 사용된다면, 요소가 실제 클릭할 수 있게 되기 전에 암시적 대기에 의해 스크립트를 계속 실행할 수도 있다.
3. Fluent wait
유연한 대기는 Explicit Wait의 확장된 방법이다.
기존의 Explicit Wait 기능을 지원하고 추가적으로 polling 빈도 수를 지정할 수 있다.
Implicit Wait와 Explicit Wait의 default polling period는 500ms이다.
polling은 리얼 타임 웹을 구현하기 위해 서버와 클라이언트간에 송수신 주기를 조절하는 방식을 의미한다.
polling 주기가 짧을수록 서버 부하가 커지고 실시간성이 높아진다.
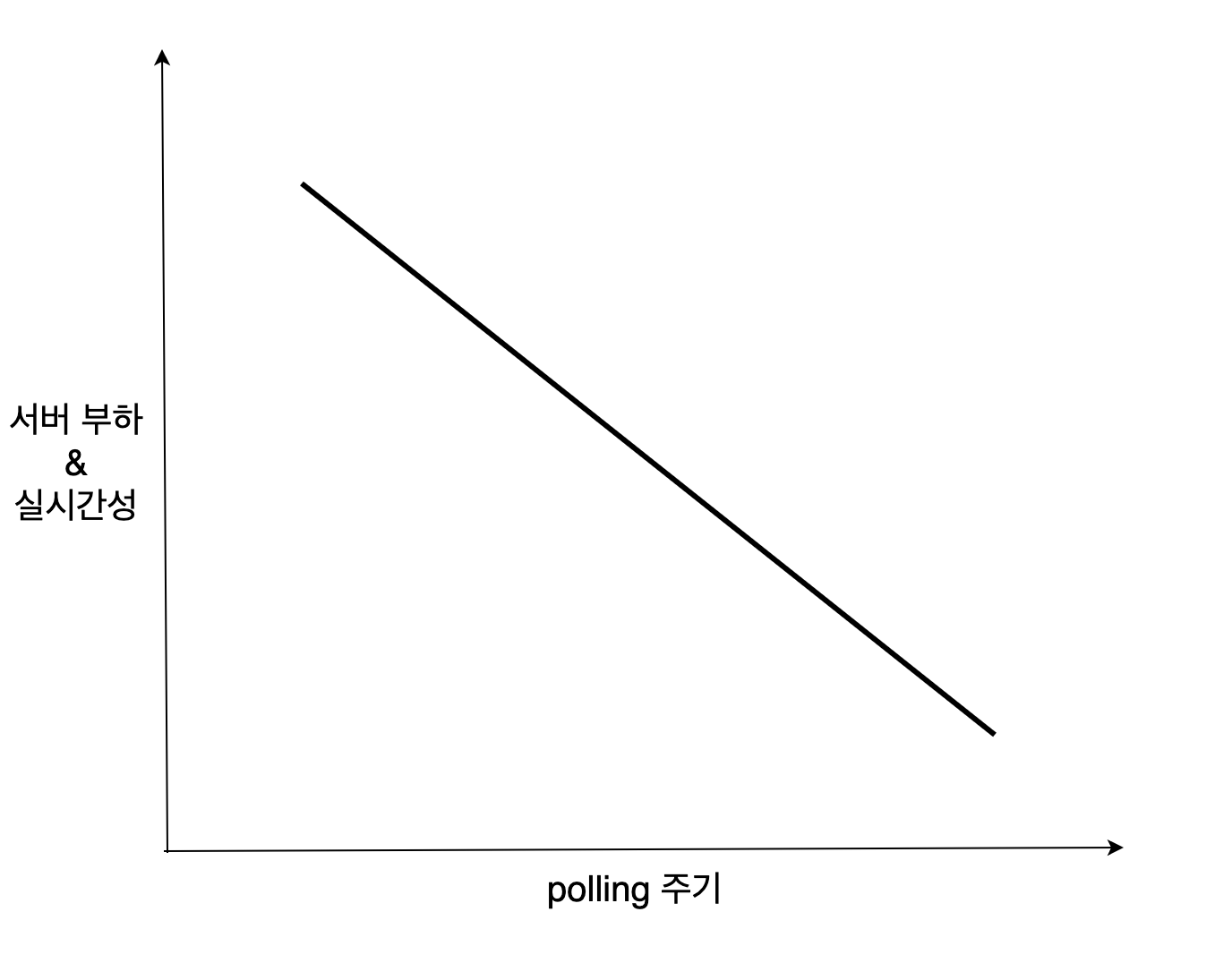
Selenium에서 말하는 polling은 조건을 만족하는 element를 찾는 일종의 동기화하는 행위를 의미한다.
pollingEvery() 함수는 polling 빈도수를 조절하는 함수이고 ignoring() 함수는 polling 중 무시할 exception을 정의할 때 사용한다.
Wait wait = new FluentWait(WebDriver reference)
.withTimeout(Duration.ofSeconds(SECONDS))
.pollingEvery(Duration.ofSeconds(SECONDS))
.ignoring(Exception.class);
📌 thread.sleep()를 사용을 지양해야 하는 이유
Selenium의 wait을 사용하지 말고 그냥 java에서 지원하는 thread.sleep() 함수를 사용하면 되지 않냐고 생각할 수 있을 것이다.
하지만 wait을 사용하면 thread.sleep()을 사용할 때보다 더 적은 대기 시간으로 로직을 구현할 수 있다.
2초만에 로딩되는 element를 찾기 위해 thread.sleep()를 이용해서 5초 동안 대기한다고 가정해보자.
결과적으로 그 차이인 3초만큼 실행 시간이 늘어나게 된다.
Selenium의 wait은 최대 대기 시간 전에 조건에 해당하는 element를 찾으면 그 즉시 대기를 종료하기 때문에 더 효율적이다.
Selenium 사용하기
- 의존성 추가
- 드라이버 설치
1. 의존성 추가
build.gradle 파일에 다음 행을 추가해주자
implementation 'org.seleniumhq.selenium:selenium-java:4.8.1'
2. 드라이버 설치
WebDriver를 사용하기 위해선 사용할 브라우저에 해당하는 드라이버를 설치해야한다.
Chrome을 사용할 경우 아래의 사이트에 접속해서 Driver를 다운로드 받는다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 111, please download ChromeDriver 111.0.5563.64 If you are using Chrome version 110, please download ChromeDriver 110.0.5481.77 If you are using Chrome version 109, please download ChromeDriver 109.0.5414.74
chromedriver.chromium.org
설치된 zip 파일의 압축을 풀고 /usr/local/bin 경로로 드라이버를 복붙한다.
> cp chromedriver /usr/local/bin
이후 자바단에서 설치된 드라이버 경로를 명시해주면 된다.
System.setProperty("webdriver.chrome.driver", "/usr/local/bin/chromedriver");
WebDriver driver = new ChromeDriver(); // success!!
예제 코드
예제 코드는 '네이버'와 '카카오' 두 회사에서 채용 공고 데이터를 크롤링하는 과정을 다뤄보았다.
CrawlerController
크롤러가 최초로 호출되는 클래스이다.
Collection Injection을 통해 JobCrawler 인터페이스를 구현하는 모든 구현체들을 DI하도록 했다.
Task Scheduler를 사용하여 일정한 시간마다 동작하도록 구현했다.
@RestController
public class CrawlerController {
private final List<JobCrawler> jobCrawlers;
public CrawlerController(List<JobCrawler> jobCrawlers) {
this.jobCrawlers = jobCrawlers;
}
@Scheduled(cron = "0 0 0 1/1 * ? *")
public void crawling() {
for (JobCrawler jobCrawler : jobCrawlers) {
jobCrawler.crawling();
}
}
}cron expression은 cron trigger를 설정할 때 사용하는 표현식으로 아래의 포스팅을 참고하면 쉽게 이해할 수 있다.
https://sjparkk-dev1og.tistory.com/32
Spring - Scheduler 설정 방법 및 사용방법
Spring - Scheduler 설정 방법 및 사용방법 일정 시간마다 실행해줘야하는 기능이 있어서 찾아보니 스프링에서 제공해주는 스프링 스케줄러를 이용하기로 했다. 스프링 스케줄러는 일정한 시간간격
sjparkk-dev1og.tistory.com
TaskSchedulerConfig
애플리케이션에서 @Scheduled 어노테이션을 사용하기 위해선 @EnableScheduling 어노테이션을 추가해줘야한다.
@EnableScheduling
public class TaskSchedulerConfig {
}
JobCrawler
crawling 추상 메서드를 포함하는 인터페이스이다.
public interface JobCrawler {
void crawling();
}NaverRecruitCrawler
네이버 채용 홈페이지를 크롤링하는 클래스이다.
JobCrawler 인터페이스를 구현한다.
crawling 메서드를 오버라이딩하는데 다음의 과정을 수행한다.
- Chrome Web Driver 실행
- 상세 공고 링크 리스트에 담기
- 네이버 채용 홈페이지는 무한 스크롤 페이지이기 때문에 전체 데이터가 랜더링될 때까지 scroll down하는 action을 실행한다.
- 네이버 채용홈페이지는 공고마다 annoId를 부여한다.
- 메인 페이지의 모든 annoId를 찾아서 리스트에 담는다.
- 상세 공고 페이지 리스트를 순회하여 Recruit 타입 오브젝트로 파싱
- 상세 공고 페이지 url : https://recruit.navercorp.com/rcrt/view.do?annoId={annoId}
- DB에 저장
- upsert 하여 중복되어 데이터가 저장되는 것을 방지한다
HTML 파싱 중에 예외가 발생하면 InvalidUrlException, ElementParseException 같은 커스텀 예외가 발생하고 인터셉터가 이를 가로채서 예외 처리 작업을 수행한다.
@Component
@Slf4j
public class NaverRecruitCrawler implements JobCrawler {
private final RecruitMapper recruitMapper;
private static final String NAVER_URL = "<https://recruit.navercorp.com/rcrt/list.do?subJobCdArr=1010001%2C1010002%2C1010003%2C1010004%2C1010005%2C1010006%2C1010007%2C1010008%2C1010020%2C1020001%2C1030001%2C1030002%2C1040001%2C1050001%2C1050002%2C1060001&sysCompanyCdArr=&empTypeCdArr=&entTypeCdArr=&workAreaCdArr=&sw=&subJobCdData=1010001&subJobCdData=1010002&subJobCdData=1010003&subJobCdData=1010004&subJobCdData=1010005&subJobCdData=1010006&subJobCdData=1010007&subJobCdData=1010008&subJobCdData=1010020&subJobCdData=1020001&subJobCdData=1030001&subJobCdData=1030002&subJobCdData=1040001&subJobCdData=1050001&subJobCdData=1050002&subJobCdData=1060001>";
private static final String NAVER_DETAIL_URL = "<https://recruit.navercorp.com/rcrt/view.do?annoId=>";
private static final long SCROLL_PAUSE_TIME = 3000L;
public NaverRecruitCrawler(RecruitMapper recruitMapper) {
this.recruitMapper = recruitMapper;
}
@Override
@Transactional
public void crawling() {
log.info("================== Naver Recruits Crawling Start ===================");
WebDriver driver = runWebDriver();
List recruitDetailLinks = getRecruitDetailLinks(driver);
List crawledRecruits = parseLinkToRecruit(driver, recruitDetailLinks);
for (Recruit crawledRecruit : crawledRecruits) {
recruitMapper.upsertRecruits(crawledRecruit);
}
driver.quit();
log.info("================== Naver Recruits Crawling End =====================");
}
private WebDriver runWebDriver() {
// WebDriver 경로 설정
System.setProperty("webdriver.chrome.driver", "/usr/local/bin/chromedriver");
// WebDriver option
ChromeOptions options = new ChromeOptions();
options.addArguments("--start-maximized"); // 최대크기로
options.addArguments("--headless"); // Browser를 띄우지 않음
options.addArguments("--disable-gpu"); // GPU를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--no-sandbox"); // Sandbox 프로세스를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--disable-popup-blocking"); // 팝업 무시
options.addArguments("--disable-default-apps"); // 기본앱 사용안함
return new ChromeDriver(options);
}
private List getRecruitDetailLinks(WebDriver webDriver) {
List result = new ArrayList<>();
WebDriverWait wait = new WebDriverWait(webDriver, 10);
JavascriptExecutor javascriptExecutor = (JavascriptExecutor) webDriver;
try {
webDriver.get(NAVER_URL);
Long beforeHeight = (Long) javascriptExecutor.executeScript(
"return document.body.scrollHeight;");
while (true) {
javascriptExecutor.executeScript("window.scrollTo(0, document.body.scrollHeight);");
Thread.sleep(SCROLL_PAUSE_TIME);
Long afterHeight = (Long) javascriptExecutor.executeScript(
"return document.body.scrollHeight;");
if (beforeHeight.equals(afterHeight)) {
break;
} else {
beforeHeight = afterHeight;
}
}
List webElements = wait.until(
ExpectedConditions.visibilityOfAllElementsLocatedBy(
By.xpath("//*[@class='card_link']")));
for (WebElement e : webElements) {
String annoId = e.getAttribute("onclick").replaceAll("[^0-9]", "");
String link = String.format("%s%s", NAVER_DETAIL_URL, annoId);
result.add(link);
}
} catch (InvalidArgumentException e) {
webDriver.quit();
throw new InvalidUrlException();
} catch (InterruptedException e) {
}
return result;
}
private List parseLinkToRecruit(WebDriver webDriver, List recruitDetailLinks) {
List result = new ArrayList<>();
WebDriverWait wait = new WebDriverWait(webDriver, 10);
for (String link : recruitDetailLinks) {
try {
webDriver.get(link);
String title = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//h4[@class='card_title']"))).getText();
String career = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='card_info']/dd[4]"))).getText();
String workerType = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='card_info']/dd[5]"))).getText();
String duration = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='card_info']/dd[6]"))).getText();
String dueDate = null;
if (duration.contains("~")) {
String[] temp = duration.split(" ~ ");
dueDate = temp[1];
}
result.add(new Recruit.Builder(title, CompanyType.NAVER.getValue(), link)
.career(career)
.dueDate(dueDate)
.workerType(workerType)
.build());
} catch (InvalidArgumentException e) {
webDriver.quit();
throw new InvalidUrlException();
} catch (WebDriverException e) {
webDriver.quit();
throw new ElementParseException();
}
}
return result;
}
}📌 xpath란?
DOM(Document Object Model)문서 내의 모든 요소를 정의하고 해당 요소에 접근하기 위한 경로
KakaoRecruitCrawler
카카오 채용 홈페이지를 크롤링하는 클래스이다.
JobCrawler 인터페이스를 구현한다.
crawling 메서드를 오버라이딩하는데 다음의 과정을 수행한다.
- Chrome WebDriver 실행
- 카카오 채용 메인 페이지에 접속해서 채용 상세 페이지 링크 List에 담기
- 카카오 채용 메인 페이지는 네이버와 다르게 페이지 테이블 형식으로 구현되어 있다.
- https://careers.kakao.com/jobs?page={currentPage} 경로로 조회할 수 있는 모든 상세 공고 url 읽기
- List를 순회하여 Recruit 타입 오브젝트로 파싱
- 상세 공고 페이지 url : https://careers.kakao.com/jobs/{id}
- DB 데이터와 크롤링한 데이터 중복 제거
- HashSet 자료구조를 사용해서 O(N) 시간 복잡도로 구현
- 크롤러 중복 제거시 Collection의 removeAll() 함수를 사용하고 removeAll()은 내부적으로 contains() 와 remove() 함수를 호출한다. Contains()와 remove() 함수의 시간복잡도가 O(1)인 HashSet 자료구조를 사용해서 결과적으로 O(N)의 시간 복잡도로 구현했다.
- HashSet 객체의 contains()는 내부적으로 hashCode() 호출한다. 따라서 Recruit 객체의 동등성과 동일성을 보장하기 위해 HashCode()와 equals()를 overriding 해줬다.
- DB에 저장

@Slf4j
@Component
public class KakaoRecruitCrawler implements JobCrawler {
private final RecruitMapper recruitMapper;
private static final String KAKAO_URL = "<https://careers.kakao.com/jobs>";
public KakaoRecruitCrawler(RecruitMapper recruitMapper) {
this.recruitMapper = recruitMapper;
}
@Override
@Transactional
public void crawling() {
log.info("================== Kakao Recruits Crawling Start ===================");
WebDriver webDriver = runWebDriver();
List recruitDetailLinks = getRecruitLinks(webDriver);
List recruits = parseLinkToRecruit(webDriver, recruitDetailLinks);
List recruitsToAdd = deduplicate(recruits);
for (Recruit recruit : recruitsToAdd) {
recruitMapper.save(recruit);
}
webDriver.quit();
log.info("================== Kakao Recruits Crawling End =====================");
}
private WebDriver runWebDriver() {
// WebDriver 경로 설정
System.setProperty("webdriver.chrome.driver", "/usr/local/bin/chromedriver");
// WebDriver option
ChromeOptions options = new ChromeOptions();
options.addArguments("--start-maximized"); // 최대크기로
options.addArguments("--headless"); // Browser를 띄우지 않음
options.addArguments("--disable-gpu"); // GPU를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--no-sandbox"); // Sandbox 프로세스를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--disable-popup-blocking"); // 팝업 무시
options.addArguments("--disable-default-apps"); // 기본앱 사용안함
return new ChromeDriver(options);
}
private List deduplicate(List recruits) {
List findRecruits = recruitMapper.findByCompany(CompanyType.KAKAO.getValue());
Set recruitsSet = new HashSet<>(recruits);
Set findRecruitsSet = new HashSet<>(findRecruits);
recruitsSet.removeAll(findRecruitsSet);
return new ArrayList<>(recruitsSet);
}
private List parseLinkToRecruit(WebDriver webDriver, List recruitDetailLinks) {
List result = new ArrayList<>();
WebDriverWait wait = new WebDriverWait(webDriver, 20);
for (String link : recruitDetailLinks) {
try {
webDriver.get(link);
String title = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//strong[@class='tit_jobs']"))).getText();
String career = null;
if (title.contains("신입") && title.contains("경력")) {
career = "경력무관";
} else if (title.contains("경력")) {
career = "경력";
} else if (title.contains("신입")) {
career = "신입";
}
String workerType = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='list_info']/dd[2]"))).getText();
String dueDate = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='list_info']/dd[3]"))).getText();
String address = wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//dl[@class='list_info']/dd[4]"))).getText();
result.add(new Builder(title, CompanyType.KAKAO.getValue(), link)
.career(career)
.dueDate(dueDate)
.workerType(workerType)
.address(address)
.build());
} catch (InvalidArgumentException e) {
webDriver.quit();
throw new InvalidUrlException();
} catch (WebDriverException e) {
webDriver.quit();
throw new ElementParseException();
}
}
return result;
}
private List getRecruitLinks(WebDriver webDriver) {
List result = new ArrayList<>();
int currentPage = 1;
WebDriverWait wait = new WebDriverWait(webDriver, 20);
while (true) {
try {
webDriver.get(String.format("%s?page=%d", KAKAO_URL, currentPage));
wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//*[@id=\\"mArticle\\"]/div/ul[@class='list_jobs']")));
} catch (InvalidArgumentException e) {
webDriver.quit();
throw new InvalidUrlException();
} catch (WebDriverException e) { // 마지막 페이지
break;
}
try {
List webElements = wait.until(
ExpectedConditions.visibilityOfAllElementsLocatedBy(
By.xpath("//ul[@class='list_jobs']/child::a")));
for (WebElement e : webElements) {
String href = e.getAttribute("href");
if (href == null) {
webDriver.quit();
throw new ElementParseException();
}
result.add(String.format("%s", href));
}
} catch (WebDriverException e) {
webDriver.quit();
throw new ElementParseException();
}
currentPage += 1;
}
return result;
}
}
Recruit
채용 공고 엔티티 클래스이다.
다음의 이유로 빌더 패턴을 적용했다.
- 객체 생성시 필수 인자와 선택 인자를 구별
- 객체 생성시 가독성 향상
- 객체의 immutable함 보장
@Getter
@Alias("recruit")
@ToString
public class Recruit {
private Long id;
private String title;
private String career;
private String dueDate;
private String company;
private String address;
private String workerType;
private String link;
private LocalDateTime addDateTime;
private LocalDateTime updateDateTime;
public Recruit() {
}
protected Recruit(Long id, String title, String career, String dueDate, String company,
String address, String workerType, String link, LocalDateTime addDateTime,
LocalDateTime updateDateTime) {
this.id = id;
this.title = title;
this.career = career;
this.dueDate = dueDate;
this.company = company;
this.address = address;
this.workerType = workerType;
this.link = link;
this.addDateTime = addDateTime;
this.updateDateTime = updateDateTime;
}
private Recruit(Builder builder) {
id = builder.id;
title = builder.title;
career = builder.career;
dueDate = builder.dueDate;
company = builder.company;
address = builder.address;
workerType = builder.workerType;
link = builder.link;
addDateTime = builder.addDateTime;
updateDateTime = builder.updateDateTime;
}
@Override
public int hashCode() {
return Objects.hash(getTitle(), getCompany(), getLink());
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Recruit)) {
return false;
}
Recruit recruit = (Recruit) o;
return getTitle().equals(recruit.getTitle()) && getCompany().equals(recruit.getCompany())
&& getLink().equals(recruit.getLink());
}
public static class Builder {
// 필수 매개변수
private final String title;
private final String company;
private final String link;
// 선택 매개변수
private Long id = 0L;
private String career = null;
private String dueDate = null;
private String address = null;
private String workerType = null;
private LocalDateTime addDateTime = null;
private LocalDateTime updateDateTime = null;
public Builder(String title, String company, String link) {
this.title = title;
this.company = company;
this.link = link;
}
public Builder id(Long id) {
this.id = id;
return this;
}
public Builder career(String career) {
this.career = career;
return this;
}
public Builder dueDate(String dueDate) {
this.dueDate = dueDate;
return this;
}
public Builder address(String address) {
this.address = address;
return this;
}
public Builder workerType(String workerType) {
this.workerType = workerType;
return this;
}
public Builder addDateTime(LocalDateTime addDateTime) {
this.addDateTime = addDateTime;
return this;
}
public Builder updateDateTime(LocalDateTime updateDateTime) {
this.updateDateTime = updateDateTime;
return this;
}
public Recruit build() {
return new Recruit(this);
}
}
}
GlobalExceptionHandler
Interceptor를 통해서 예외 처리 로직을 분리했다.
크롤러 동작시 InvalidUrlException, ElementParseException 같은 JobCrawlerException 타입 런타임 예외가 발생하면 인터셉터가 이를 가로채서 일괄 처리한다.
아래 코드는 에러 발생시 개발자에게 메일로 공지하는 방식으로 구현했다.
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler extends ResponseEntityExceptionHandler {
@Value("${admin.email}")
private String adminEmail;
private final MailSendManager mailSendManager;
public GlobalExceptionHandler(MailSendManager mailSender) {
this.mailSendManager = mailSender;
}
@ExceptionHandler(value = {JobCrawlerException.class})
protected ResponseEntity<ErrorResponse> handleJobCrawlerException(JobCrawlerException e)
throws MessagingException {
log.error("JobCrawlerException : {}", e.getErrorCode());
mailSendManager.sendMail(adminEmail, "Job Crawler RuntimeException 발생", String.format(
"exception name : %s\\nerror code : %s\\nerror message : %s", e.getClass().toString(),
e.getErrorCode(), e.getErrorCode().getDetail()));
return ErrorResponse.toResponseEntity(e.getErrorCode());
}
}
코드 참조
https://github.com/KIM-KYOUNG-OH/ChatBot
GitHub - KIM-KYOUNG-OH/ChatBot: 금일 업데이트된 채용 공고 및 뉴스 기사를 제공하는 카카오톡 챗봇입니
금일 업데이트된 채용 공고 및 뉴스 기사를 제공하는 카카오톡 챗봇입니다. Contribute to KIM-KYOUNG-OH/ChatBot development by creating an account on GitHub.
github.com
정리
이번 포스팅에선 Selenium 라이브러리를 사용해서 웹 크롤러를 제작한 과정을 공유해보았다.
웹 크롤러를 개발하면서 고도화하거나 부족한 부분이 많은 것 같은데 다음 포스팅에서는 아래의 키워드에 대해서 다뤄볼 계획이다.
- 배치 서버를 통해 크롤링 부하 분산
- DB side 중복 제거 vs java side 중복 제거
- InterruptedException 처리
- 에러 발생시 Logging & Notification 전략
- E2E 테스트
Reference
https://www.selenium.dev/documentation/
https://bonigarcia.dev/webdrivermanager/
https://www.guru99.com/implicit-explicit-waits-selenium.html#fluent-wait
https://www.tcpschool.com/xml/xml_xpath_pathExpression
https://deonggi.tistory.com/162
http://happinessoncode.com/2017/10/09/java-thread-interrupt/